Flash Attention from a Beginner's Point of View
23rd March, 2025Transformers are amazing, right? Their attention mechanisms like self-attention and multi-head attention make them super powerful for understanding context in text, translations, and more. But there’s a catch: traditional attention can be a memory hog and slowpoke, especially when dealing with long sequences. Enter Flash Attention, a clever optimization that makes attention faster and more efficient without sacrificing accuracy. Let’s dive in!
This is just merely part I of what Flash attention is in upcoming parts of Flash attention we will be diving deeper into flash attention internals and implementation in pytorch
What is Flash Attention and Why is it Needed?
Attention, as we know, computes a weighted sum of values (V) based on how relevant each key (K) is to a query (Q). The problem? For a sequence of length N, the attention mechanism needs to create an N × N attention score matrix. That’s a lot of memory! For example, if N = 10,000 (think a long document), you’re storing 100 million numbers just for that matrix. GPUs, which power these models, choke on this because they have limited memory, and moving data back and forth slows everything down.
Flash Attention is a way to compute attention without ever fully building that giant N × N matrix in memory. Instead, it processes the data in smaller chunks (or "tiles") and does the math on-the-fly. It’s like solving a puzzle piece by piece instead of laying out the whole picture at once. This saves memory, speeds things up, and lets Transformers handle much longer sequences—like entire books—without crashing.
Why is it Needed?
-
Memory Efficiency: Traditional attention’s memory usage grows quadratically (N²), while Flash Attention scales linearly (N).
-
Speed: It reduces redundant data movement between GPU memory layers.
-
Scalability: It unlocks Transformers for super-long sequences (e.g., 64k tokens instead of 512).
How Does Flash Attention Work?
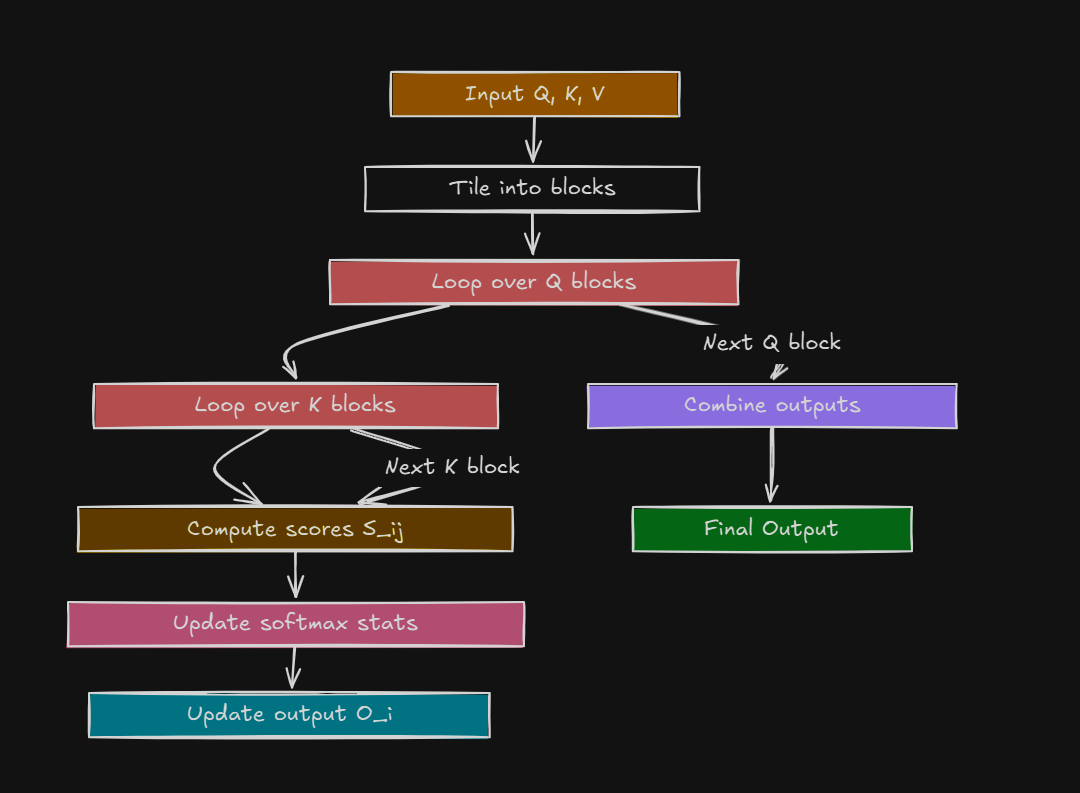
Let’s break it down :
-
Compute the dot product of Q and K to get the attention scores (N × N matrix).
-
Scale and apply softmax to turn scores into weights.
-
Multiply those weights by V to get the output.
Flash Attention says, “Why store that huge score matrix?” Instead, it:
-
Splits Q, K, and V into smaller blocks (like cutting a big cake into slices).
-
Computes attention for one block at a time, using a technique called tiling.
-
Updates the output incrementally, keeping only what’s needed in memory.
Here’s the trick: it avoids storing the full attention score matrix by recomputing intermediate results when necessary and using clever math to keep the softmax accurate across blocks. This happens entirely on the GPU’s fast memory (SRAM), skipping the slower main memory (HBM).
Step-by-Step:
-
Input: Q, K, and V matrices (say, each is N × d, where d is the embedding size).
-
Tiling: Break them into smaller chunks (e.g., blocks of size B × d, where B << N).
-
Inner Loop: For each block of Q, compute attention with all blocks of K and V, but only store tiny temporary results.
-
Softmax Trick: Use a running normalization to combine results across blocks without ever needing the full matrix.
-
Output: Build the final attention output block-by-block.
The result? Same output as regular attention, but way less memory and faster computation.
Mathematical Representation
Let’s keep it simple but precise. Regular attention computes:
Attention(Q, K, V) = softmax(QKT√dk)V
Where:
-
\( Q, K, V \in \mathbb{R}^{N \times d} \) (N = sequence length, d = dimension).
-
\( QK^T \in \mathbb{R}^{N \times N} \) (the big, problematic score matrix).
Flash Attention avoids materializing \( QK^T \) fully. Instead:
-
Split \( Q \) into blocks \( Q_1, Q_2, ..., Q_m \) (each \( B \times d \)).
-
Split \( K \) and \( V \) similarly into \( K_1, K_2, ..., K_m \) and \( V_1, V_2, ..., V_m \).
-
For each block \( Q_i \):
- Compute \( S_i = Q_i K^T \) (small \( B \times N \) matrix).
- Scale: \( S_i / \sqrt{d_k} \).
- Apply softmax incrementally, tracking running sums and normalization constants.
- Compute \( O_i = \text{softmax}(S_i)V \) and add to the output.
The magic is in the incremental softmax, which uses two extra variables (a max and a sum) to stitch everything together accurately without the full matrix.
With Flash Attention, the operator is smarter. They only look at one section of the stage at a time (a block), figure out who’s important in that moment, and adjust the spotlight right away. They keep a tiny notepad (fast GPU memory) with just enough info to move to the next section. The play (computation) goes on smoothly, and the audience (model) still sees the full story—no one notices the operator’s trick!
Flash Attention in the Transformer Architecture
Flash Attention fits right into the Transformer’s attention layers:
-
Encoder: Replaces self-attention with Flash Attention to process input sequences efficiently.
-
Decoder: Handles masked self-attention (for previous tokens only) and cross-attention (connecting to the encoder) with the same block-wise trick.
It’s plug-and-play: same Transformer, just faster and leaner.
Why Is Flash Attention a Big Deal?
-
Longer Sequences: Models can now process tens of thousands of tokens (e.g., 64k) instead of hitting a wall at 512 or 1024.
-
Energy Savings: Less memory movement = less power, which matters for big AI training runs.
Intuition: Flash Attention as a Spotlight
Remember our theater analogy? In regular attention, the spotlight operator (Attention) scans the entire stage (all tokens) at once, writing down a huge list of who’s important (the N × N matrix) before deciding where to shine the light. With a big stage, that list gets unwieldy, and the operator runs out of paper (memory).
With Flash Attention, the operator is smarter. They only look at one section of the stage at a time (a block), figure out who’s important in that moment, and adjust the spotlight right away. They keep a tiny notepad (fast GPU memory) with just enough info to move to the next section. The play (computation) goes on smoothly, and the audience (model) still sees the full story—no one notices the operator’s trick!