Transformers are a type of neural network architecture which is
popularly used for text generations, machine translations, etc. But
before transformers, models like RNNs and LSTMs were used for sequence
data. Unfortunately, they had issues with long-range dependencies
because the sequential processing made it hard to parallielize and
capture context from far away in sequence
Transformers solved this issue by using attention mechanism to weigh the
importance of different parts of the input allowing model to focus on
relevant parts regardless of their position.
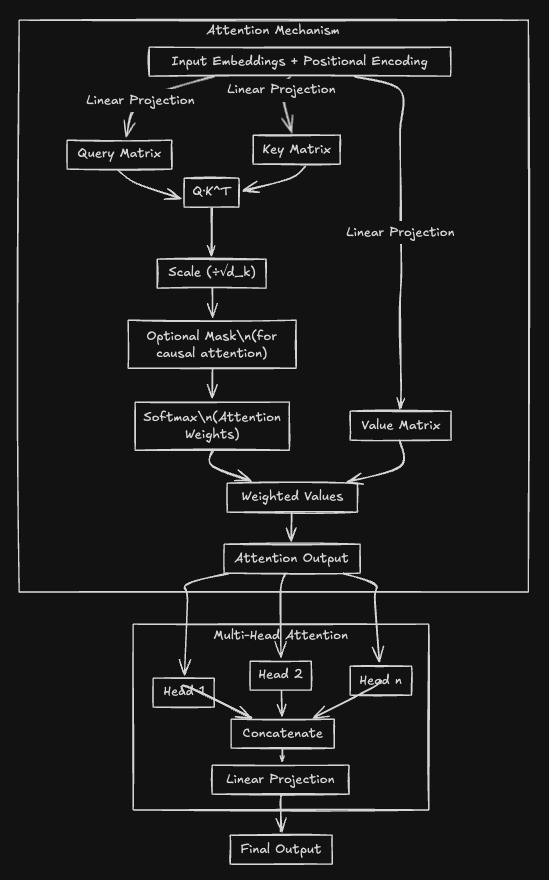
This is what attention under the hood looks like, we will be deep diving
into every component one by one. Coming back to our topic which is
What is Attention and Why is it needed ?
So attention is a way to compute a weights sum of values (from the
input) where the weights are determined by the relevance between the
query and the keys.
How ?
In the context of a sentance, each word (or token) has a query, key and
value vectors. The query from a word is compared with the keys of all
other words to determine how much attention to pay to each one. The
value are then aggregated based on these attention weights.
How do we exactly generate these query, key and value vectors ?
They usually come from linear transformations of the input embeddings.
So each input token is embedded into a vector, and then multiplied by
weight matrices \(Wq, Wk, Wv\) to get the query, key and value vectors.
Then, the attention scores between token are calculated using the dot
product of the query and key vectors. These scores are scaled by the
square root of the dimension of the key vectors to prevent the dot
products from getting too large, which could lead to vanishing
gradients.
After scaling, a softmax is applied to convert the scores into
probabilities (weights) that sum to 1. These weights are then used to
take a weighted average of the value vectors. The result is the output
of the attention mechanism for each position. This process is called
self-attention because each position attends to all positions in the
same sequence.
Mathematical Representation
Let \( \mathbf{x} \in \mathbb{R}^{d} \) be the input embedding for a
token, where \( d \) is the dimensionality of the embedding space.
The query, key, and value vectors are generated by applying linear
transformations to the input embedding:
where \( \mathbf{A} \in \mathbb{R}^{n \times n} \) is the attention
score matrix, \( n \) is the number of tokens, and \( \sqrt{d} \) is the
scaling factor to prevent vanishing gradients.
Note: \( \top \) denotes the transpose operation, and \( \mathbb{R}^{d
\times d} \) represents the set of \( d \times d \) matrices with
real-valued entries.
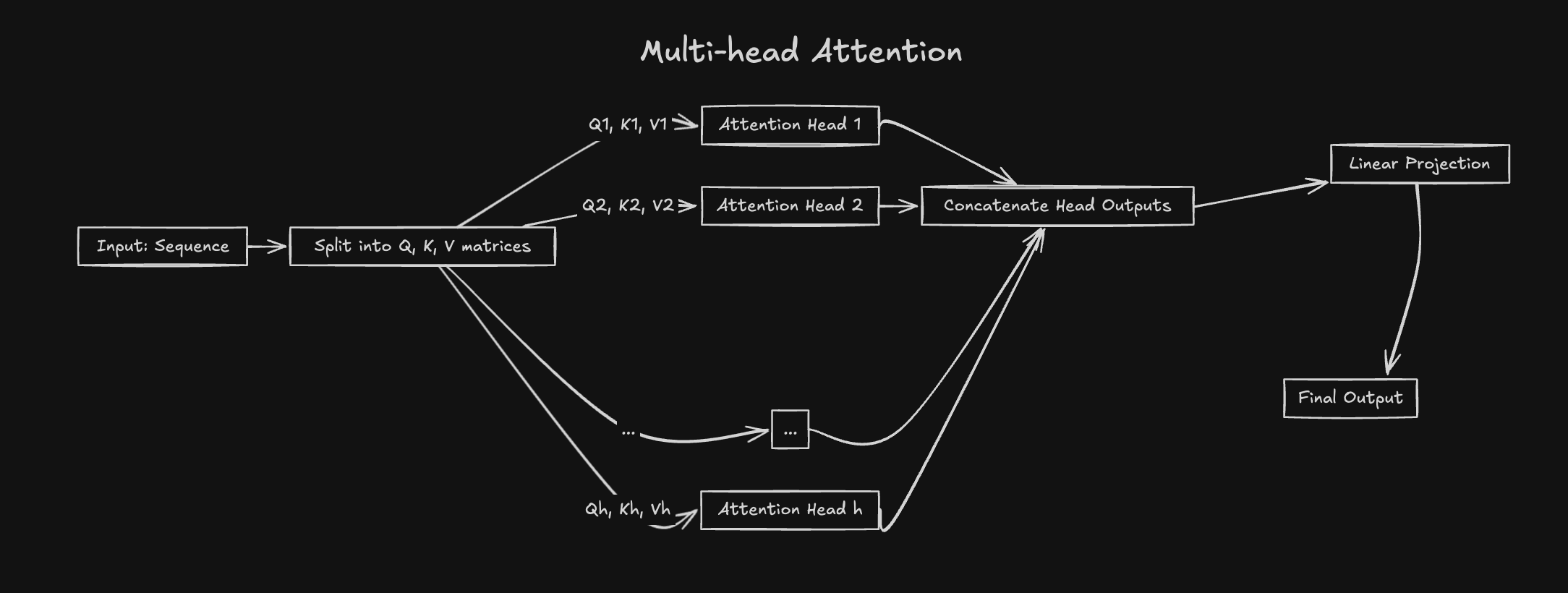
Multi-Head Attention : Attention on RedBull
Transformers don't stop at one Attention mechanism - they use
Multi-Head Attention, instead of
computing a single attention mechanism, the model splits the input into
multiple heads, each computing their own attention. This allows the model
to focus on different parts of the input in different ways. The outputs
from each head are concatenated and then linearly transformed again to get
the final output
Why do they do this? Maybe to capture different types of relationships or
dependencies in the data, this also allows the model to attent to multiple
relationship in the data at once, making it incredibly flexible and
expressive
We will discuss more about Multi-Head Attention in the upcoming blog :)
Self-Attention
In Transformers, the most common type of attention is Self Attention, where Q, K and V all come from the same input sequence. This means every token in the sequence can attend to every other token, including itself, For example:
The cat slept because it was tired
Self-Attention lets "it" focus heavily on "cat"to understand the reference
This biredirectional (or non-bidirectional) awareness is what makes Transformers so good at capturing context, unlike RNNs, which only look backward or forward
K (Key matrix): What the model can offer (a representation of all tokens).
V (Value matrix): The actual content of the tokens to be weighted and combined.
)
Steps in Computation:
Dot Product: Compute \( Q \cdot K^T \), resulting in a score matrix of shape.
Scaling: Normalize by dividing by \( \sqrt{d_k} \), ensuring stable gradients.
Softmax: Apply the softmax function along the last dimension (keys) to obtain attention weights.
Weighted Sum: Multiply by \( V \), obtaining the final attention output.
Attention in the Transformer Architecture
The Transformer consists of an Encoder and a Decoder, both stacked with multiple layers (e.g., 6 or 12). Attention plays different roles in each:
Encoder
Uses Self-Attention to process the input sequence (e.g., a sentence in English).
Each layer refines the representation, passing it to the next.
Decoder
Uses Masked Self-Attention to process the output sequence (e.g., a translation in French). “Masked” means it only attends to previous positions to prevent cheating by looking at future tokens during training.
Also uses Cross-Attention to connect the Decoder to the Encoder, letting the output attend to the input (e.g., aligning French words with English ones).
Intuition : Attention as a Spotlight
Single most phrase which made me understand attention is
Think of Attention as a spotlight operator in a theater. The Query is the director saying, “Focus on the lead actor!” The Keys are all the actors on stage, and the Values are their lines. The spotlight (Attention) adjusts its beam based on who’s most relevant, illuminating the scene dynamically as the play unfolds.